函数的引用
首先,看一下下面的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14def test1():
print("--- in test1 func----")
#调用函数
test1()
#引用函数
ret = test1
print(id(ret))
print(id(test1))
#通过引用调用函数
ret()
运行结果:1
2
3
4--- in test1 func----
140212571149040
140212571149040
--- in test1 func----
一图胜千言: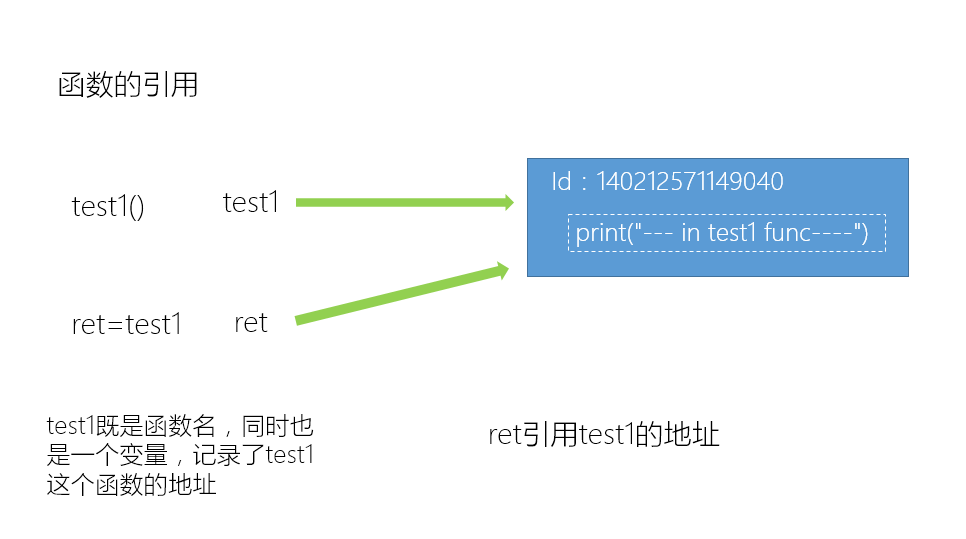
闭包
在函数内部再定义一个函数,并且这个函数用到了外边函数的变量,那么将这个函数以及用到的一些变量称之为闭包。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#定义一个函数
def test(number):
def test_in(number_in):
print("in test_in 函数, number_in is %d"%number_in)
return number+number_in
#这里返回的就是闭包的结果
return test_in
#给test函数赋值,这个20就是给参数number
ret = test(20)
#注意这里的100其实给参数number_in
print(ret(100))
#注意这里的200其实给参数number_in
print(ret(200))
运行结果:1
2
3
4
5in test_in 函数, number_in is 100
120
in test_in 函数, number_in is 200
220
闭包再理解
内部函数对外部函数作用域里变量的引用(非全局变量),则称内部函数为闭包。1
2
3
4
5
6
7
8# closure.py
def counter(start=0):
count=[start]
def incr():
count[0] += 1
return count[0]
return incr
启动python解释器1
2
3
4
5
6
7
8
9
10
11>>>import closeure
>>>c1=closeure.counter(5)
>>>print(c1())
6
>>>print(c1())
7
>>>c2=closeure.counter(100)
>>>print(c2())
101
>>>print(c2())
102
nonlocal访问外部函数的局部变量(python3)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20def counter(start=0):
def incr():
nonlocal start
start += 1
return start
return incr
c1 = counter(5)
print(c1())
print(c1())
c2 = counter(50)
print(c2())
print(c2())
print(c1())
print(c1())
print(c2())
print(c2())
看一个闭包的实际例子:1
2
3
4
5
6
7
8
9def line_conf(a, b):
def line(x):
return a*x + b
return line
line1 = line_conf(1, 1)
line2 = line_conf(4, 5)
print(line1(5))
print(line2(5))
这个例子中,函数line与变量a,b构成闭包。在创建闭包的时候,我们通过line_conf的参数a,b说明了这两个变量的取值,这样,我们就确定了函数的最终形式(y = x + 1和y = 4x + 5)。我们只需要变换参数a,b,就可以获得不同的直线表达函数。由此,我们可以看到,闭包也具有提高代码可复用性的作用。
如果没有闭包,我们需要每次创建直线函数的时候同时说明a,b,x。这样,我们就需要更多的参数传递,也减少了代码的可移植性。
闭包思考:
1.闭包似优化了变量,原来需要类对象完成的工作,闭包也可以完成。
2.由于闭包引用了外部函数的局部变量,则外部函数的局部变量没有及时释放,消耗内存。

